
DeepSeek Engram
Brace Yourself for V4

DeepSeek shook the AI world and financial markets at the start of 2025, and it now seems to be dropping hints that it is looking to do the same again this year in 2026. The Chinese company has released two papers already this year, with one of them describing their new Engram architecture. We should be seeing the effectiveness or ineffectiveness and impact of this new technique soon as they are slated to launch their new DeepSeek-V4 model in mid-February, and if last year has shown us anything, it is that DeepSeek is perhaps the most influential AI lab outside of the US at the moment.
Let us first establish some context surrounding this new model and why it could potentially represent something important, or perhaps more of the same old. In December 2024 and January 2025, DeepSeek, which was relatively unknown at the time, released its DeepSeek-V3 model and DeepSeek-R1 model. While the consensus is that they did not surpass any frontier models from the Western AI labs, they did come remarkably close and it was a real moment of realisation that the Chinese AI labs were catching up and chasing hard. What was more impressive though was the claims by DeepSeek that their models were trained on a fraction of the computing resources and chips that the Western AI models had been trained on so far. This had massive implications for the market as firstly it caused many to question whether the AI infrastructure buildout and massive capex being spent on data centres was truly necessary. It was a large factor, combined with some others, in NVIDIA suffering a temporary $600 billion market cap decline. Furthermore, this DeepSeek moment was especially significant because it challenged one of the West’s primary competitive advantages: access to superior chips like NVIDIA’s and a chipmaking ecosystem anchored by companies like TSMC and ASML—hardware now restricted from export to China.
It provided the basis for hope and fear depending on your perspective, that architectural gains could be enough to create the best models and AI products in the present and future even with computing limitations. DeepSeek claimed it was able to create such a competitive model despite utilising multitudes less compute power due to architectural innovation in its algorithms such as utilising mixture of experts. While people argue about the true precise amount of compute used by DeepSeek in training V3, no one argues that it was definitely significantly more efficient in the training process than other models at the time and represented a true contribution to the architectural designs of models in the AI field.
However, the initial panic subsided relatively quickly after the release of V3. Within weeks, the industry had processed the implications and reached a more nuanced conclusion: DeepSeek’s new models hadn’t invalidated the importance of compute but rather it had demonstrated that compute could be used more efficiently. The innovations in DeepSeek’s architecture, particularly its sophisticated mixture-of-experts design, didn’t eliminate the need for scaling; they made scaling more productive and that applying the novel and superior architecture insights you could get even better models when combined with increasingly larger computational capabilities. In other words, companies realised that you still wanted to build out the compute power as much as you can, because this combined with superior architecture would yield even greater results than before. So while DeepSeek announced itself as an important player in the AI ecosystem, it ended up being yet another bookmark in the story of AI as most of the Western and Chinese AI labs went about business as usual for the rest of the year, pushing forward with expanding compute power and innovating architectural design combined with their data to keep iterating their models. The allure of DeepSeek is accentuated by the background of its founding story. Rather than emerging from Silicon Valley’s venture capital machine or a tech giant like Google, it comes from a quantitative hedge fund in China, with a reportedly genius founder essentially going out on his own, tinkering and creating and inventing. The narrative goes that Liang Wenfeng couldn’t effectively communicate his AI ideas or vision to the investors in his hedge fund and they didn’t understand or weren’t interested in this tangent from the core quantitative trading business. But because he had control over High Flyer and its resources, he didn’t need their permission or buy-in; he simply went out and did it anyway, funding the research himself through the profits from the hedge fund. There’s a romantic quality to this narrative that stands in stark contrast to the typical AI company today that goes through the standard practices of raising large amounts of venture capital, having a wealth of resources at its disposal and being entrenched in the mainstream technology circles of Silicon Valley. Instead, we get the image of Liang Wenfeng pursuing what feels like an intellectually-driven project, an underdog utilising armed with only his wit to compete against the Goliaths of his day. Although this kind of romantic story can be overstated as the project does stem from a multi-billion dollar quant fund, the increased efficiency and natural limitations faced by DeepSeek certainly paints this image of scrappy innovation versus industrial machinery.
Now back to DeepSeek Engram. So as we have mentioned, a year or so has passed and the markets and AI world has more or less gone back to the same as before, with a large focus on architecture and increasing compute power to improve the quality of models. This is especially beneficial for the US as their main advantage has been in the superiority of their chips and hardware ecosystem and it is projected to remain this way for the foreseeable future with Chinese companies struggling to catch up in the chipmaking department. But DeepSeek has released new papers in 2026, promising new architectures that will yet again bring about a leap in efficiency by fundamentally rethinking how AI models handle different types of knowledge. I think it’s pretty clear that DeepSeek is expecting their new model to have quite the effect based upon the releases of these papers and signs of confidence teeming throughout, and even some online reports have leaked that its coding ability is expected to potentially surpass ChatGPT’s. In fact, in the Engram paper, they have placed a telling reference within the paper explaining its architecture. It’s a phrase “Only Alexander the Great could tame the horse Bucephalus.” The tale goes that King Philip II of Macedon was presented with a magnificent but wild horse named Bucephalus, whose name meant “ox-headed” due to the distinctive shape of his brow. The animal was extraordinarily powerful but completely unmanageable and none of the experienced horseman could ride him, so he was deemed worthless. Philip ordered the horse taken away, but his young son Alexander begged for one chance to tame the beast. What happened next became legend. While the grown men had attempted to dominate Bucephalus through strength and traditional horsemanship, the young Alexander had been observing. He noticed something everyone else had missed: Bucephalus was frightened by his own shadow moving on the ground. Every time the horse saw this dark shape shifting beneath him, he would rear and bolt. Alexander’s solution was elegant in its simplicity. He turned Bucephalus toward the sun, eliminating the shadow from the horse’s field of vision. Then he ran alongside the animal until it was calm, before finally mounting and riding him successfully. Bucephalus became Alexander’s legendary warhorse, carrying him across thousands of miles of conquest from Greece to India, until the horse’s death in battle around 326 BCE. Alexander founded a city, Bucephala, in his honour. The lesson wasn’t about raw power but about ingenuity, understanding and doing what others are unable to see. DeepSeek seems to be positioning itself as the Alexander the Great of AI: the lab that will tame the AI beast not through overwhelming resources but by observing what others have missed.
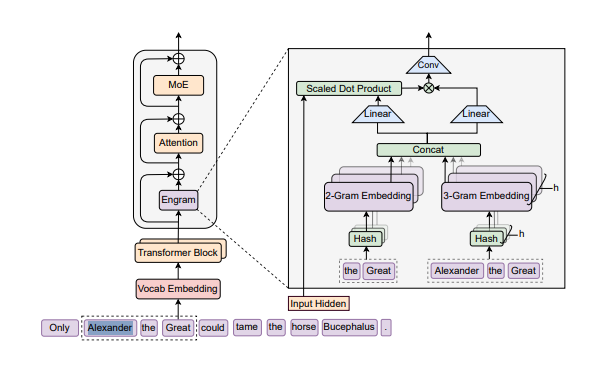
So what actually is Engram? Traditional large language models treat every token generation as equally expensive, running complex calculations through billions of parameters whether they’re deriving a novel mathematical proof or reciting “To be or not to be.” This is computationally wasteful and is the equivalent of using the same brute force approach regardless of whether you’re facing a genuinely difficult challenge or a routine task. To put it as simply as possible, Engram proposes a solution: maintain a massive external memory structure to handle the routine stuff, freeing the core neural network to focus on actual reasoning tasks. When an AI model recalls that Paris is the capital of France, it doesn’t need to activate billions of parameters and perform complex matrix multiplications. It just requires factual retrieval, not reasoning. Engram offloads these memorisation tasks to a separate lookup table, preserving the neural network’s capacity for tasks that genuinely require “thinking.” This isn’t entirely unprecedented. The concept echoes earlier work in neural-symbolic AI, retrieval-augmented generation (RAG), and even classic computer science data structures. What makes Engram potentially significant is the scale and integration—turning what has traditionally been more of a small component of the overall solution into a fundamental architectural principle. Other labs have explored similar territory but DeepSeek appears to be making the most aggressive bet on this split-architecture approach. This structure allows the model to decouple memory from reasoning, theoretically increasing efficiency by ensuring the heavy computational “thinking” power is reserved for novel or complex problems.
However, there is still the fundamental tension in DeepSeek’s story. Even if Engram works brilliantly, even if V4 demonstrates remarkable capabilities at a fraction of the computational cost, the likely outcome isn’t a sustained competitive advantage. It’s that Western labs will study the architecture, implement their own versions, and combine those efficiency gains with their substantially larger compute budgets to regain the lead or pull further ahead. Until there comes a point in time when continued compute scale for whatever reason does not improve AI models, many of these architectural innovations will not lead to sustained competitive advantage. If DeepSeek V4 is indeed yet another substantial moment in the efficiency and quality of AI models, the question will be the same yet again, is this merely another bookmark in the road of AI, and other firms will adopt the architectural techniques if they are useful, and perpetuate the rapid expansion and improvement of compute power, thus continuing the status quo, or could there be a true and lasting paradigm shift in how companies view the best way to advance AI research and progress. Only time will tell what the future holds, but I do believe this will be an interesting moment in the AI world this year, particularly if the increased efficiency in architectural design leads not only to more catch-up but genuine superiority of a Chinese AI model for the first time. It would serve well to remember that one of the most important and credible AI researchers in the world right now, Ilya Sutskever, has been on record saying that under the current paradigm, he believes that while scaling compute will bring about incremental improvements, an age of research is needed to bring about the next wave of substantial improvements that can take AI to the technological state that so many of its proponents believe possible: as some form of supernatural entity or technology.
*Disclaimer: This information is for general informational purposes only and does not constitute financial, investment, or professional advice. The author may hold positions in the assets or companies discussed.
Bonnefin Research is a free publication focused on better investment thinking. Subscribe and share to support the work, and join the discussion in the comments as we continue building this community.